之前已经写了一篇安装 R-CNN 的文章了,现在就要使用自己的数据集训练 R-CNN 了。
这篇文章记录了我用人脸数据集来训练 R-CNN,并且使用训练后的 R-CNN 模型检测出图片中的人脸的过程。
构建数据集
查看 R-CNN 的 demo 程序的源代码 rcnn_demo.m 发现,有两个已经训练好的模型可供使用,它们分别是使用 PASCAL VOC 2007 数据集和 ImageNet ILSVRC 2013 数据集训练好的模型,前者可识别 20 个类型,后者可识别 200 个类型。然而这 220 个类型并不包括人脸,所以需要自己训练。
下载数据集
我下载的是香港中文大学多媒体实验室的 CelebA 数据集,这是一个人脸数据集,一共有 20 多万张图片。官方也提供了某度盘的链接。以下是我下载的文件:
1. 有环境的图片(In-The-Wild Images)
在度盘的 Img/img_celeba.7z 文件夹中。由于图片非常多,这个压缩包很大,所以作者进行了分卷压缩,有 14 个文件(img_celeba.7z.001 到 img_celeba.7z.014),一共 9 个多 G。我在 Windows 用度盘客户端下的,不然速度会时不时地归零。下载下来后也在 Windows 下的命令提示符中进行分卷的合并:
copy /b img_celeba.7z.* img_celeba.7z很慢啊,因为太大了。合并好了会生成一个新的压缩包 img_celeba.7z,然后解压。
2. 标注信息(Bounding Box Annotations)
训练和测试的时候,需要告诉程序一张图片哪个地方才是人脸,所以需要标注框,标注信息提供了每张图片中人脸标注框的坐标。在度盘的 Anno/list_bbox_celeba.txt,直接下载即可。
转换数据集
其实作者提供了使用自己的数据集训练 R-CNN 的教程,但是写得很粗略,主要就是需要准备三个函数:
- 返回描述图片和类型的结构体(参考
imdb/imdb_from_voc.m) - 返回感兴趣区域(即标注框)的结构体(参考
imdb/roidb_from_voc.m) - 提供评估功能(参考
imdb/imdb_eval_voc.m)
也可以把自己的数据集转换成 PASCAL VOC 的格式,这样就可以重用作者的代码了,我就是使用的这种方式。
数据集结构
我以前有下过 PASCAL VOC 2007 数据集,先用 tree -d 命令看下目录结构吧:
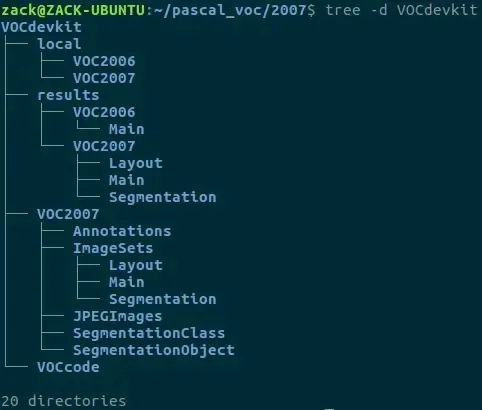
接下来仿照此结构,构建自己的数据集。
先把 rcnn/datasets/VOCdevkit2007 链接到存放 CelebA 数据集的目录(我是 ~/pascal_voc/celeba/VOCdevkit):
$ ln -sf ~/pascal_voc/celeba/VOCdevkit ~/rcnn/datasets/VOCdevkit2007再在 VOCdevkit 下添加一些文件夹,结构如下:
VOCdevkit
├── results
│ └── VOC2007
│ └── Main
├── VOC2007
│ ├── Annotations
│ ├── ImageSets
│ │ └── Main
│ └── JPEGImages
└── VOCcode下面是每个文件夹的说明:
VOC2007/Annotations存放JPEGImages文件夹中图片的标注信息,与图片文件同名且一一对应,为xml格式。VOC2007/ImageSets/Main存放四个txt文件:train.txt、val.txt、trainval.txt、test.txt,分别定义训练、验证、训练和验证、测试四种数据集中的图片,这些文件里的每一行文本都是一个 image identifier,其实也就是图片的文件名。VOC2007/JPEGImages存放所有图片文件。VOCcode存放加载、处理数据集的代码。直接将 PASCAL VOC 2007 数据集中的VOCdevkit/VOCcode文件夹复制到这里就行。results/VOC2007/Main测试的时候会在此文件夹下临时存放一个文件,没有这个路径的话会报错:
Error using fprintf
Invalid file identifier. Use fopen to generate a valid file identifier.准备图片
PASCAL VOC 2007 数据集中包含 20 类图片,但是我只需要检测一类,就是人脸,所以到底使用多少张图片合适呢?我自己写了个 Python 脚本,读取 Annotations 文件夹中的 xml 文件分析了一下每个类型在所有图片中出现的次数,结果如图:
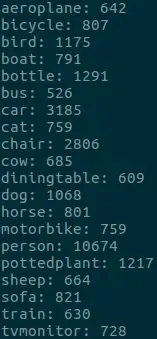
感觉每个类型出现的次数也不多,那我就选 CelebA 数据集中前 1000 张图片吧,应该够用了。把 CelebA 数据集中文件名为 000001.jpg 到 001000.jpg 的图片放到 VOCdevkit/VOC2007/JPEGImages 里。
准备标注文件
PASCAL VOC 2007 数据集的标注文件为 xml 格式的,以 000002.xml 为例:
<annotation> <folder>VOC2007</folder> <!-- 图片的文件名 --> <filename>000002.jpg</filename> <source> <database>The VOC2007 Database</database> <annotation>PASCAL VOC2007</annotation> <image>flickr</image> <flickrid>329145082</flickrid> </source> <owner> <flickrid>hiromori2</flickrid> <name>Hiroyuki Mori</name> </owner> <!-- 图片宽、高、深度 --> <size> <width>335</width> <height>500</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>train</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <!-- 标注框信息 --> <bndbox> <xmin>139</xmin> <ymin>200</ymin> <xmax>207</xmax> <ymax>301</ymax> </bndbox> </object> </annotation>xml
CelebA 提供的标注信息都存放在 list_bbox_celeba.txt 中。此文本除 1、2 行外,其余行均为各图片的标注信息,格式为
| 列数 | 内容 | 例子 |
| 1 | 图片文件名 | 000002.jpg |
| 2 | 标注框左上角 x 坐标 | 72 |
| 3 | 标注框左上角 y 坐标 | 94 |
| 4 | 标注框宽 | 221 |
| 5 | 标注框高 | 306 |
需要利用这些信息来构建 xml 格式的标注文件,当然,手动转换是不现实的,所以我写了个 Python 脚本来转换,使用了 PASCAL VOC 2007 数据集中的标注文件 000002.xml 作为模板,仅仅将模板中的 filename、size、bndbox 元素修改了就行,其他的不动。代码如下:
import xml.etree.cElementTree as ET import cv2 # 使用 000002.xml 作为模板,因为它只有一个 object 元素 template_file = '/home/zack/pascal_voc/2007/VOCdevkit/VOC2007/Annotations/000002.xml' # 生成的 xml 文件保存的路径 target_dir = '/home/zack/pascal_voc/celeba/VOCdevkit/VOC2007/Annotations/' # 所有图片的路径 image_dir = '/home/zack/pascal_voc/celeba/VOCdevkit/VOC2007/JPEGImages/' # 给出所有标注信息的文件,由 CelebA 提供 bbox_file = '/home/zack/celeba/list_bbox_celeba.txt' # 图片数量 image_num = 1000 bboxes = open(bbox_file, 'r') for bbox in bboxes.readlines()[2 : image_num + 2]: bb_info = bbox.split() image_file = bb_info[0] x_1 = int(bb_info[1]) y_1 = int(bb_info[2]) width = int(bb_info[3]) height = int(bb_info[4]) tree = ET.parse(template_file) root = tree.getroot() # filename root.find('filename').text = image_file # size sz = root.find('size') im = cv2.imread(image_dir + image_file) sz.find('width').text = str(im.shape[0]) sz.find('height').text = str(im.shape[1]) sz.find('depth').text = str(im.shape[2]) # object obj = root.find('object') obj.find('name').text = 'face' bb = obj.find('bndbox') bb.find('xmin').text = str(x_1) bb.find('ymin').text = str(y_1) bb.find('xmax').text = str(x_1 + width) bb.find('ymax').text = str(y_1 + height) xml_file = image_file.replace('jpg', 'xml') tree.write(target_dir + xml_file) print xml_file bboxes.close() print 'Done'py
执行以上脚本后,所有的标注框文件就已经生成了。如果出现 ImportError: No module named cv2 的错误,执行以下命令安装 OpenCV 的 Python 接口:
$ sudo apt-get install python-opencv`准备数据集配置文件
配置文件即 ImageSets/Main 下的四个文件,定义四种数据集,这四种数据集中的图片会被分别用来做训练、验证、训练和验证、测试。我看了看 PASCAL VOC 2007 中四个数据集的分配,发现每个数据集中的图片应该是随机抽取的,但需要满足一定的条件: trainval 和 test 约为总图片数的一半,但不重合,即选出其中一个数据集的图片后,另一个数据集的图片就是选剩下的图片了,而 train 和 val 约占 trainval 的一半,同样不重合。所以我也用这个比例来制作这四个数据集吧。依然写了个 Python 脚本(Python 真是太好用了 🤣):
import os import random # 生成的 txt 文件存放的目录 target_dir = '/home/zack/pascal_voc/celeba/VOCdevkit/VOC2007/ImageSets/Main/' # 所有图片的路径 image_dir = '/home/zack/pascal_voc/celeba/VOCdevkit/VOC2007/JPEGImages/' image_files = os.listdir(image_dir) image_ids = [image_id.replace('.jpg', '\n') for image_id in image_files] image_ids.sort() # trainval & test trainval = open(target_dir + 'trainval.txt', 'w') test = open(target_dir + 'test.txt', 'w') trainval_ids = random.sample(image_ids, len(image_ids) / 2) trainval_ids.sort() i = 0 for image_id in image_ids: if i < len(trainval_ids) and image_id == trainval_ids[i]: trainval.write(image_id) i+=1 else: test.write(image_id) trainval.close() test.close() # train & val train = open(target_dir + 'train.txt', 'w') val = open(target_dir + 'val.txt', 'w') train_ids = random.sample(trainval_ids, len(trainval_ids) / 2) train_ids.sort() i = 0 for trainval_id in trainval_ids: if i < len(train_ids) and trainval_id == train_ids[i]: train.write(trainval_id) i+=1 else: val.write(trainval_id) train.close() val.close() print 'Done'py
执行以上脚本后,所有的配置文件就已经生成了。
修改相关代码
修改 VOCdevkit/VOCcode/VOCinit.m,81-101 行定义了 PASCAL VOC 2007 数据集中图片的 20 种分类,将这些分类全部删除,替换成一种分类 —— face,即替换成 VOCopts.classes={'face'};。
训练模型
训练过程主要参考了作者提供的使用 PASCAL VOC 2007 数据集来训练 R-CNN 的教程,大致步骤如下:
计算候选区域 → 调优 CNN → 提取特征 → 训练与测试
计算候选区域
作者提供的教程的第一步就是提取特征(extract features),那是因为他给出的是使用 PASCAL VOC 2007 数据集来训练 R-CNN 的教程,然而我是用自己的数据集来训练,所以需要先使用 Selective Search 算法计算一下候选区域。
作者在 rcnn/selective_search 文件夹下提供了使用 Selective Search 算法计算候选区域的函数 selective_search_boxes.m。我写了一个 MATLAB 函数来调用这个函数,生成储存候选区域的文件:
function selective_search_boxes_generator(chunk) mat_file = sprintf('./data/selective_search_data/voc_2007_%s.mat', chunk); if exist(mat_file, 'file') fprintf('File exists\n'); return end image_ids = load(sprintf('./datasets/VOCdevkit2007/VOC2007/ImageSets/Main/%s.txt', chunk)); image_num = size(image_ids, 1); images = cell(1, image_num); boxes = cell(1, image_num); fprintf('Computing candidate regions...\n'); th = tic(); fast_mode = true; im_width = 500; parfor i = 1 : image_num image_id = sprintf('%06d', image_ids(i)); images{1, i} = image_id; image_file = sprintf('./datasets/VOCdevkit2007/VOC2007/JPEGImages/%s.jpg', image_id); im = imread(image_file); box = selective_search_boxes(im, fast_mode, im_width); % 需要取整,否则之后调优训练的 loss 会一直为 0 boxes{1, i} = round(box); fprintf('%s.jpg\n', image_id); end fprintf('Finished, costs %.3fs\n', toc(th)); fprintf('Saving MAT file to %s...\n', mat_file); save(mat_file, 'images', 'boxes'); fprintf('Done\n');matlab
调用此函数前,需要先移走 rcnn/data/selective_selective_data 文件夹下的 voc_2007_train.mat、voc_2007_val.mat、voc_2007_trainval.mat、voc_2007_test.mat 四个文件,然后在 rcnn 目录下执行
>> selective_search_boxes_generator('train');
>> selective_search_boxes_generator('val');
>> selective_search_boxes_generator('trainval');
>> selective_search_boxes_generator('test');总共花费了将近 1 个小时。执行完毕后,在 selective_selective_data 文件夹下又生成了刚才移走的四个文件,不过现在,这四个文件里就是我自己的数据集的候选区域信息了。
调优 CNN
这一步,将计算出的候选区域作为输入,送入 CNN 进行训练。使用预训练的模型 ilsvrc_2012_train_iter_310k(ImageNet ILSVRC 2012 数据集训练 AlexNet 网络生成的模型)初始化网络参数,然后再将上一步得到的候选区域送入该网络进行训练,即调优(fine-tune)。
作者在教程中并没有给出调优 CNN 的步骤,同样因为教程是面向 PASCAL VOC 2007 数据集的,如果下一步直接使用作者提供的用 PASCAL VOC 2007 数据集调优后的 CNN 模型 finetune_voc_2007_trainval_iter_70k 来提取特征,最终的精度就会有损失,所以需要使用自己的数据集对 CNN 进行调优。调优的步骤参考了作者提供的使用 PASCAL VOC 2012 数据集来调优 CNN 的教程。
加载数据集
将 trainval、test 两个数据集加载到 Workspace:
>> imdb_trainval = imdb_from_voc('datasets/VOCdevkit2007', 'trainval', '2007');
>> imdb_test = imdb_from_voc('datasets/VOCdevkit2007', 'test', '2007');创建 Window Files
>> rcnn_make_window_file(imdb_trainval, 'external/caffe/examples/pascal-finetuning');
>> rcnn_make_window_file(imdb_test, 'external/caffe/examples/pascal-finetuning');在 rcnn/external/caffe/examples/pascal-finetuning 文件夹下生成了 window_file_voc_2007_trainval.txt 和 window_file_voc_2007_test.txt 两个文本文件。
使用 Caffe 进行调优
退出 MATLAB,使用 cd 命令进入 rcnn 目录,将调优使用的 prototxt 文件复制到 Caffe 的相应目录中:
$ cp finetuning/voc_2007_prototxt/pascal_finetune_* external/caffe/examples/pascal-finetuning/修改 prototxt 文件:
pascal_finetune_solver.prototxt- 3 行,
test_iter: 100改成test_iter: 10,定义测试需要迭代的次数。因为后面我把pascal_finetune_val.prototxt中的batch_size设为了 50,迭代 10 次,每次 50 张图片,刚好覆盖 500 张用于测试的图片。 - 4 行,
test_interval: 1000改成test_interval: 500,定义训练迭代多少次进行一次测试。因为迭代次数不多,测试的频率就高一点吧。 - 10 行,
max_iter: 100000改为max_iter: 20000,定义最大迭代次数,作者说他在 PASCAL VOC 2012 数据集上调优,迭代了 7 万次,但是 4 万次的时候就已经饱和了,所以我就调小了点。 - 13 行,
snapshot: 10000改为snapshot: 1000,定义迭代多少次后保存一次快照,快照是当前迭代次数的模型和 solver 状态,后者可以用来恢复中断的训练,因为我中途可能会中断训练,所以就调小了点。
- 3 行,
pascal_finetune_train.prototxt- 10 行,
batch_size: 128改成batch_size: 64,如果不改的话,在我的电脑上会报显存不够的错误:Check failed: error == cudaSuccess (2 vs. 0) out of memory,我电脑是 2G 的显存。 - 305 行,
num_output: 21改成num_output: 2,表示一个类型(人脸)+ 背景。
- 10 行,
pascal_finetune_val.prototxt- 10 行,
batch_size: 128改成batch_size: 50。 - 305 行,
num_output: 21改成num_output: 2。
- 10 行,
接着,使用 cd 命令进入 external/caffe/examples/pascal-finetuning,执行
$ GLOG_logtostderr=1 ../../build/tools/finetune_net.bin pascal_finetune_solver.prototxt <到 rcnn 文件夹的路径>/rcnn/data/caffe_nets/ilsvrc_2012_train_iter_310k 2>&1 | tee log.txt开始调优训练,接下来就是漫长的等待了。
刚开始的时候就会执行一次测试:
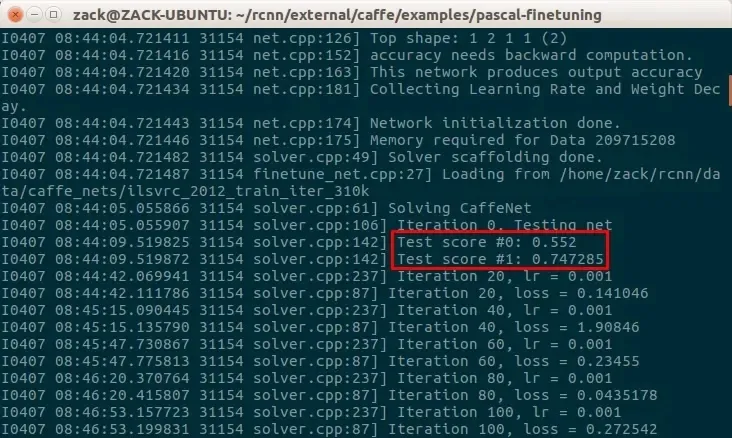
其中,Test score #0 是准确度(accuracy),Test score #1 是损失函数(loss)。可见,刚开始的时候准确度较低、损失较大。
根据设置,每迭代 500 次后会测试一次:
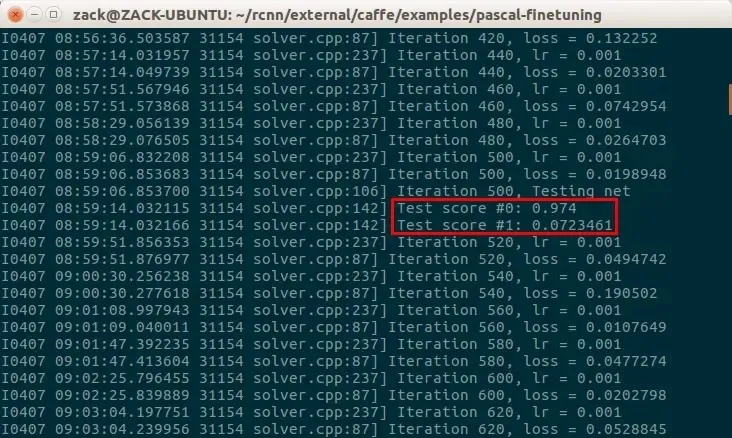
这一次准确度打到了 0.974,提高了不少,损失函数也降到比较小了。迭代 1000 次后会保存一次快照:
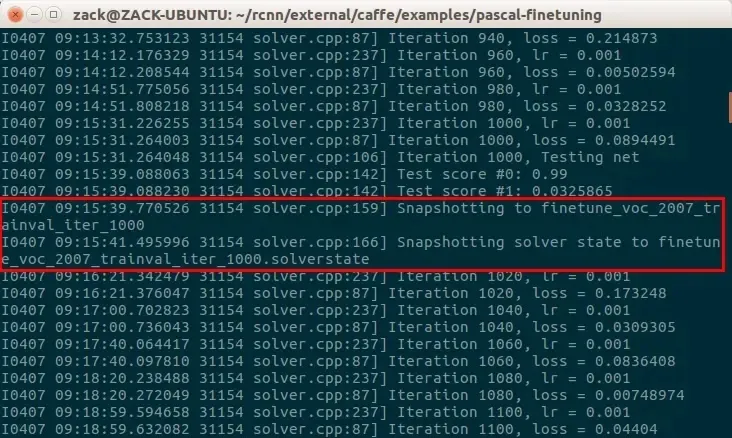
其中,finetune_voc_2007_trainval_iter_1000 就是迭代 1000 次的 Caffe 模型,finetune_voc_2007_trainval_iter_1000.solverstate 是保存的 solver 状态,使用此文件可以恢复中断的训练。
花费了接近 12 个小时,2 万次迭代的训练终于完成了:
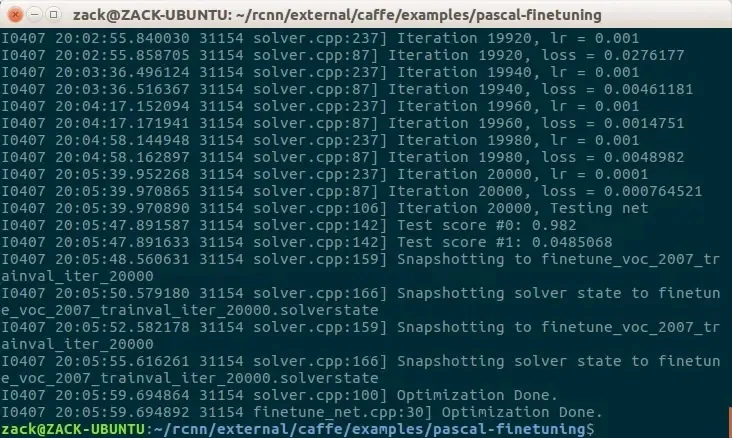
在当前目录(rcnn/external/caffe/examples/pascal-finetuning)下生成了一系列 finetune_voc_2007_trainval_iter_* 和 finetune_voc_2007_trainval_iter_*.solverstate 文件,这些就是每迭代 1000 次保存的快照,其中 finetune_voc_2007_trainval_iter_20000 就是最终的模型了。
将此模型更名为 finetune_voc_2007_trainval_iter_70k,移走 rcnn/data/caffe_nets 下的同名文件,将模型复制到此目录下,后续的提取特征等操作用的就是这个模型了。
绘制训练曲线图
Caffe 提供有一些工具,可以将训练过程中产生的一些数据绘制成曲线图。
训练过程的输出全部保存在当前目录的 log.txt 文件中,将此文件复制到 rcnn/external/caffe/tools/extra 中,使用 cd 命令进入此文件夹,执行
$ ./parse_log.sh log.txt在此文件夹下生成了 log.txt.train 和 log.txt.test 两个文件,前者是训练产生的数据,后者是测试产生的数据。再执行
$ ./plot_training_log.py.example <曲线类型参数> <图片文件名>.png log.txt其中,曲线类型支持以下八种:
| 参数 | 曲线类型 |
| 0 | Test accuracy vs. Iters |
| 1 | Test accuracy vs. Seconds |
| 2 | Test loss vs. Iters |
| 3 | Test loss vs. Seconds |
| 4 | Train learning rate vs. Iters |
| 5 | Train learning rate vs. Seconds |
| 6 | Train loss vs. Iters |
| 7 | Train loss vs. Seconds |
例如,我要绘制测试准确度随迭代次数变化的曲线图(参数为 0),并将图片保存为 test_accuracy_vs_iters.png,执行
$ ./plot_training_log.py.example 0 test_accuracy_vs_iters.png log.txt显示绘制结果:
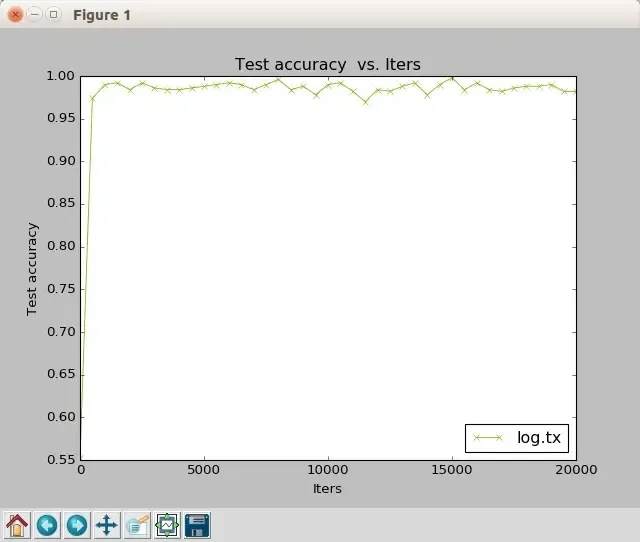
同时,图片会以指定的文件名保存在当前目录。
提取特征
打开 MATLAB,在 rcnn 目录下执行以下命令提取特征:
>> rcnn_exp_cache_features('train');
>> rcnn_exp_cache_features('val');
>> rcnn_exp_cache_features('test_1');
>> rcnn_exp_cache_features('test_2');这四个函数分别将 train、val、test(前半部分 test_1,后半部分 test_2)数据集中图片的候选区域通过神经网络,然后提取出 pool5 层的特征,以 .mat 形式存储在 rcnn/feat_cache/v1_finetune_voc_2007_trainval_iter_70k/voc_2007_* 中。
训练与测试
在 rcnn 目录下执行以下命令进行训练与测试:
>> test_results = rcnn_exp_train_and_test()总共花费了几十分钟的时间吧。
在测试结束时,程序绘制出准确率/召回率(precision/recall)曲线(关于准确率和召回率,看这里)和平均精度(average precision,AP):
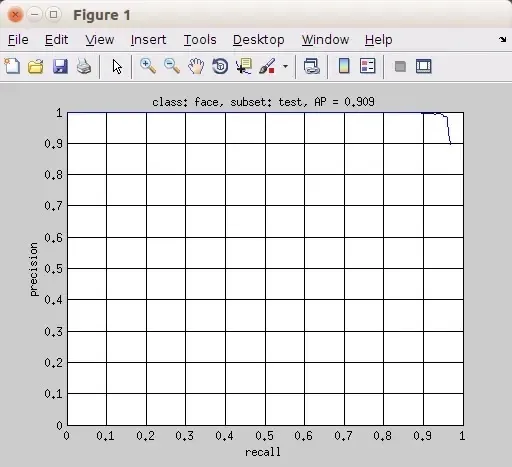
这张图片保存在 rcnn/cachedir/voc_2007_test 下,文件名为 face_pr_voc_2007_test.jpg。
最终,Command Window 输出测试结果:
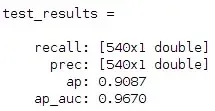
从上到下依次为召回率(recall)、准确率(prec)、平均精度(ap),最后一个 ap_auc 我也不清楚是什么 😑。
测试模型
经过训练,R-CNN 模型 rcnn_model.mat 就已经生成了,储存在 rcnn/cachedir/voc_2007_trainval 中。这个模型文件就可以用来对自己的图片进行检测了。
对作者提供的 rcnn_demo.m(在 rcnn/examples 里)稍作修改,生成一个新函数 test_my_detector,此函数能使用刚才训练好的模型 rcnn_model.mat 检测图片中的人脸:
function test_my_detector(im_path) clf; thresh = -1; if ~exist('im_path', 'var') || isempty(im_path) im_path = input('Please input the path of an image:\n'); end im = imread(im_path); rcnn_model_file = './cachedir/voc_2007_trainval/rcnn_model.mat'; if ~exist(rcnn_model_file, 'file') error('You need to train a R-CNN model first.'); end % Initialization only needs to happen once (so this time isn't counted when timing detection). fprintf('Initializing R-CNN model (this might take a little while)\n'); rcnn_model = rcnn_load_model(rcnn_model_file, true); fprintf('done\n'); % Get current timestamp th = tic; dets = rcnn_detect(im, rcnn_model, thresh); fprintf('Total %d-class detection time: %.3fs\n', length(rcnn_model.classes), toc(th)); all_dets = []; for i = 1:length(dets) all_dets = cat(1, all_dets, [i * ones(size(dets{i}, 1), 1) dets{i}]); end [~, ord] = sort(all_dets(:,end), 'descend'); for i = 1:length(ord) score = all_dets(ord(i), end); if score < 0 break; end cls = rcnn_model.classes{all_dets(ord(i), 1)}; showboxes(im, all_dets(ord(i), 2:5)); title(sprintf('det #%d: %s score = %.3f', i, cls, score)); drawnow; pause; end fprintf('No more detection with score >= 0\n');matlab
在 rcnn 目录下调用此函数:
>> test_my_detector('<图片路径>')检测了一张我弟的照片(未成年人,脸部后期做了屏蔽处理),结果如下:
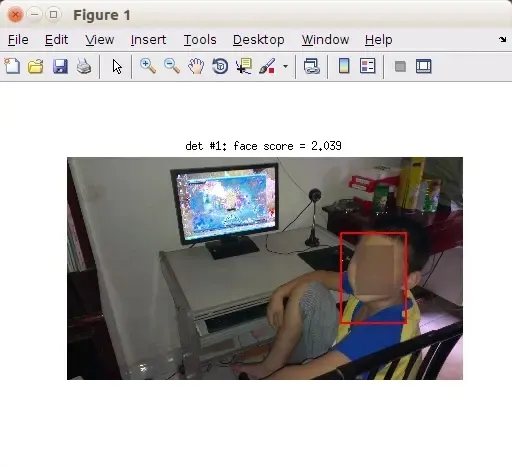
之后又陆陆续续测试了几张图片,发现有些不太清楚的人脸还是识别不出来,当然,检测的过程还很慢(大概几十秒的样子),不过这是 R-CNN 的硬伤了,想要更快的?去找 Fast R-CNN 和 Faster R-CNN 吧。
参考资料
- 用自己的数据训练Faster-RCNN - 像蜗牛一样,每天进步一点点 - CSDN博客
- Problems training on my own dataset · Issue #42 · rbgirshick/rcnn
- caffe绘制训练过程的loss和accuracy曲线 - 邬小阳 - CSDN博客
后记
自己以前对机器学习的方向根本没什么了解,然而毕业设计却选了个跟 R-CNN 有关的课题,至于为什么要选这个坑爹的课题,我真是一言难尽,此处就不提了吧。我在做这个课题的过程中,却是收获颇丰,然而一直担心自己最后做不出来,但是结果出来的那一刻,一切疑虑都烟消云散,激动的心情难以言表啊,感叹自己这一个多月的时间真的没白费。