在特定的 CSS font-family 配置下,网页的全角引号和 Emoji 的显示效果可能会不尽人意。本文介绍我对该问题进行的一些研究与适配工作。
- 由于本人对 Unicode、Python、JavaScript 的了解有限,本文可能存在不少纰漏,且本文涉及到的技术方案由本人独立思考得出,并未参考他人的实现方式,故可能不是最优的方法,敬请留意。
- 本文提及的“我的网站”并不是指本网站(code.zackzhang.net),本网站并未进行本文提及的适配优化。
全角引号的显示问题
中文字体下,无论是‘单引号’还是“双引号”都应该是全角的,因为汉字本身就是一种等宽字体,标点符号自然和文字等宽才更美观。但引号并不是中文的专属,或者说中文的全角引号和西文的半角引号 Unicode 码点(Code Point)是一样的,例如双引号都是 U+201C 和 U+201D。
如果需要对网站上的文字设置个性化字体,通常会在 font-family 中将西文字体放在中文字体前面,让前面西文字体没有的字符自动 fallback 到后面中文字体的字符,以实现西文和中文字体混排,这样做的原因通常是想从网络加载体积较小的西文字体,而体积较大的中文字体则使用操作系统自带的。例如我自己的网站:
font-family: "Barlow", "Source Han Sans SC", "Noto Sans SC", "PingFang SC", "Microsoft YaHei", sans-serif;
Barlow 是一款从 Google Fonts 加载的西文字体,而这款字体里面没有的字符(例如所有汉字)则会 fallback 到第二位的 Source Han Sans SC(思源黑体),后者则是一款中文字体。问题就在于 Barlow 这款字体里面是有引号的,显示为半角的样式,而思源黑体中的引号则显示为全角样式,那么这样的 font-family 设置让引号字形并不能 fallback 到思源黑体及之后的中文字体上,这样就导致了本该显示为中文全角样式的引号显示成了西文半角样式,可以说是一点也不美观了:
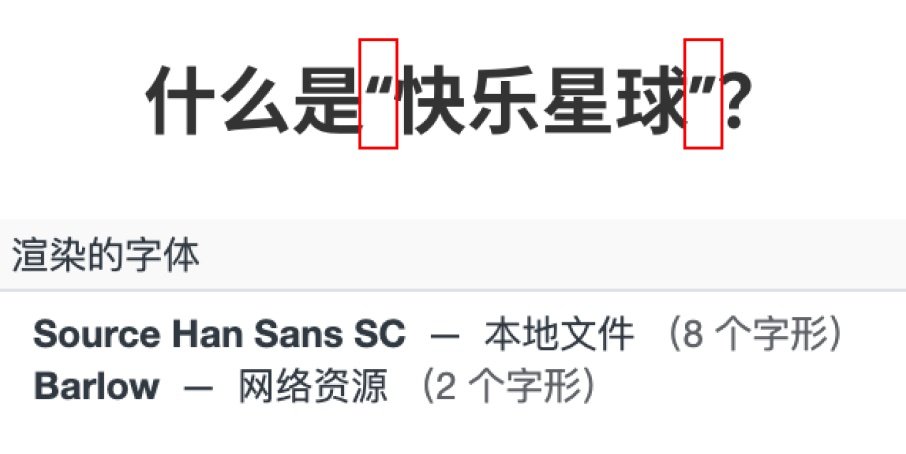
事实上所有的西文字体(应该)都包含引号,因此只要想实现中西文字体混排,即将西文字体放在中文字体前面,就必定有上述显示问题。这也是一些人推崇「直角引号」的原因,它不需要什么适配,西文字体里根本没这些符号,无论如何都会 fallback 到后面的中文字体上的,所以肯定是显示为全角的。但我个人并不喜欢去跟这个风,还是想使用现代中国大陆标准的“弯引号”,那么是一定需要做一些处理的。
Emoji 的显示问题
Emoji(绘文字)是一种起源于日本的表情字体,跟普通文字一样具有 Unicode 标准,各大操作系统的较新版本都对它有比较好的支持,比如 Apple 的系统更新大版本常常会引入一些新的 Emoji,虽然不同家系统对于同一个 Unicode 码点的 Emoji 的样式有一些区别,例如“呵呵/🙂”表情:

至于 Emoji 的显示问题,同样跟字体 fallback 有一定关系,只是要比引号复杂太多了,不同 Emoji 符号、不同 font-family 配置、不同浏览器,都可能会有不同的显示效果。还是以 Apple 系统为例,全彩 Emoji 的专用字体为 Apple Color Emoji,由于我们一般不会去自定义 Emoji 字体,所以理所当然不会在 font-family 里面去声明这个字体。即便如此,也防不住一些字体里某些字符的编码跟 Emoji 的有交集。例如在上述 font-family 的配置下,“无/🈚️”这个 Emoji 将显示为单色样式,和其他能显示为全彩样式的 Emoji 混在一起,别提有多难看了。

下面介绍一下 Unicode 的变体选择器(Variation Selector)码点。用于 Emoji 的 变体选择器 有 U+FE0E 和 U+FE0F,它们附着在 Emoji 的原始 Unicode 码点之后,决定 Emoji 应该被视作何种样式。若附着的是 U+FE0E,或者无附着,Emoji 应被视作单色样式;若附着的是 U+FE0F,Emoji 则应被视作全彩样式:

而思源黑体里面是有单色的“无/🈚”这个字符的,或者说有 U+1F21A(上图 Code 列)这个 Unicode 码点对应的字形:
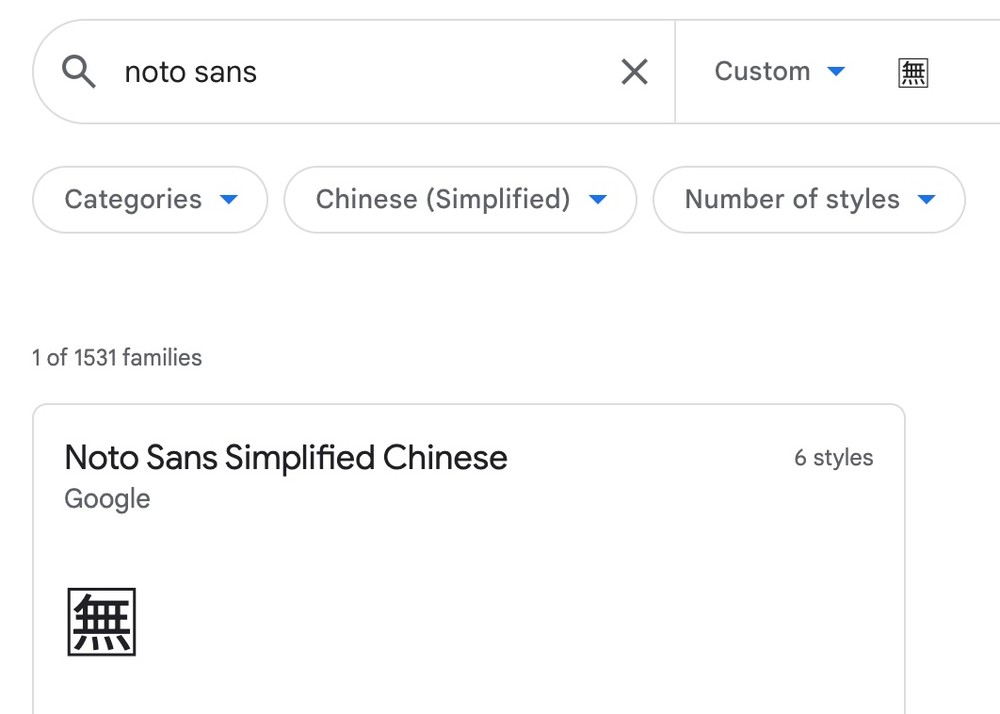
很明显全彩的“无/🈚️”应由两个 Unicode 码点 U+1F21A 和 U+FE0F 组成,然而一旦浏览器成功应用了 font-family 里面声明的思源黑体,这个字符两个 Unicode 码点中的第一个 U+1F21A 就会被显示为思源黑体的单色字形,而第二个变体选择器 U+FE0F 就被丢弃掉了(或者 fallback 到后面的字体上了,whatever,反正没有字体有它的字形)。
事实上我理解 Emoji 的变体选择器仅仅是一种“建议”,具体显示样式还是由渲染它的字体决定。因为如果将 Apple Color Emoji 放在 font-family 的最前面,即便是没有带变体选择器 U+FE0F 的单色“无/🈚”字符也会显示成全彩样式:

另外一个例子是单色的“咖啡/☕”这个字符,经过我的测试,在 Chrome(版本 114)中应用上述 font-family 会转换为全彩样式来显示,但在 Safari(版本 16.5)就会直接显示成原始的单色样式:
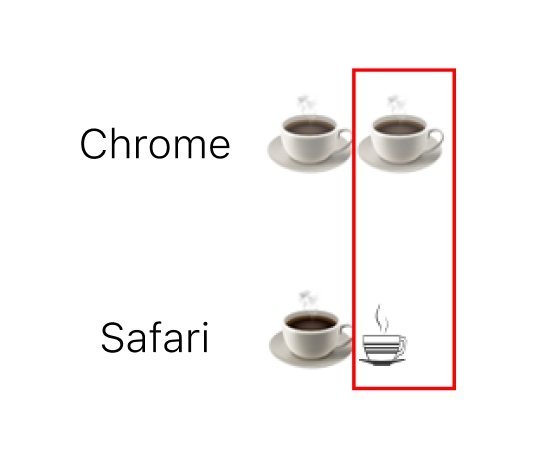
由于 font-family 中的字体都不包含这个字符,故浏览器应用的应该是 fallback 到最后的 sans-serif 默认无衬线字体。
上述例子可以得出的结论是,Emoji 的显示样式与 font-family 的配置有关,并且不同浏览器对于默认字体下的 Emoji 可能有不同的处理。当然这只是在 Apple 系统中的测试,至于 Windows 或 Android,应该也大差不差。如何做到 Emoji 样式的统一,即让每个 Emoji 在同一平台、无论何种 font-family 配置、无论哪款浏览器,都显示为相同的全彩样式呢?
两个解决方案
我能想到的解决方案分为两大类,其一是为这些特殊字符制作字体,其二是为这些特殊字符单独设置字体。
方案一:制作字体
对于引号来说,这种方案很简单。从中文字体中将引号的字形提取出来,用它们来制作一种新字体,即“提取字体子集”,网上能找到很多现成的小工具。给这款新字体取一个独特的名字,然后把它放在 font-family 第一位,即西文字体之前,由自己的服务器来托管相关字体文件。这样引号就会显示为这款新字体的样式,而不影响其他中西文字符。
这也类似我以前使用的引号适配方案,为什么说“类似”呢,因为我的实现更简单粗暴,直接从 Google Fonts 引用繁体版的思源黑体,把它放在 font-family 第一位,指定 text 参数为要引用的单/双引号(经过 URL Encode)即可:
<link href="https://fonts.googleapis.com/css2?family=Noto+Sans+TC&display=swap&text=%E2%80%9C%E2%80%9D%E2%80%99%E2%80%98" rel="stylesheet">
这样就等同于让 Google Fonts 帮我生成了一个这样的新字体,无需自己再去搞托管了。但很明显这样有个严重的缺点,如果网站访客的操作系统里装了繁体版的思源黑体,那么我设置的后序西文字体就没用了,网页上的字体将全部显示为思源黑体自带的西文样式,这也是我为什么要用繁体版的思源黑体而不是简体版的。
这样看来仿佛自己提取字形并托管才是最佳选择,但很明显这只适用于引号,因为它的字体子集简单,单/双引号一共就 4 个字符,Emoji 是没法用这个方案去解决的。一是 Emoji 太多、Unicode 标准字符集每年都在增加,也不知道哪款中西文字体里包含了 Emoji 中的哪个字符,或者默认字体下浏览器会如何显示 Emoji;二是 Emoji 字体反过来也包含了西文字体中一些字符,故跟上面讨论的现象同理,把 Emoji 字体放在 font-family 最前面是会影响西文字符的显示的,例如把 Apple Color Emoji 放在最前面会显示成这样:

Emoji 倒是显示成想要的全彩样式了,然而数字和空格直接变成等宽的了,所以这个方案应该是不适用于 Emoji 的。
方案二:单独设置字体
第二种方案的原理也很简单,把一段文字中的特殊字符找出来,将它用 <span class="xxx"></span> 包裹。class="xxx" 里面的 xxx 表示 CSS class,可以在前端用 CSS 选择器定位到这个 span,为它单独设置样式。例如我将引号和 Emoji 的 class 分别定为 full-quote 和 emoji,那么经过这样的处理,上文图片中的内容变成了这样:
什么是<span class="full-quote">“</span>快乐星球<span class="full-quote">”</span>?
咱就是说<span class="emoji">🌧️👸🏻🈚️🍉</span>谢谢
然后用 CSS 选择器为 class 为 full-quote 和 emoji 的 span 标签单独设置字体:
span.full-quote {
font-family: "Source Han Sans SC", "Noto Sans SC", "PingFang SC", "Microsoft YaHei", sans-serif;
}
span.emoji {
font-family: "Apple Color Emoji", "Segoe UI Emoji", "Segoe UI", "Segoe UI Symbol", "Noto Color Emoji", sans-serif;
}
这样引号肯定就应用的是中文字体(例如思源黑体)中的全角样式,Emoji 肯定用的是 Emoji 专用字体(例如 Apple Color Emoji)中的全彩样式,而 span 外的其他字体依然走的全局文字的 font-family,多么完美啊。所以我最终的确是采用了这种方案来做适配。
后端 Python 解析
有熟悉 Markdown 的朋友们应该看出来了,上述我采用的单独设置字体方案,其处理方式正类似于 Markdown 的解析原理,只是要解析的语法变成了特殊字符:引号或 Emoji。我的网站是由服务端来做 Markdown 解析的,编程语言是 Python,故使用了 Python-Markdown/markdown 这个库。那么为何不将对特殊字符的处理嵌入 Markdown 解析的流程中呢?查阅了 Markdown 这个库的文档,意料之中提供了相关 扩展,果断适配起来。
Markdown 的解析流程
首先简单说下我对这个库处理 Markdown 流程的理解。根据文档,原始的 Markdown 文档会经过五个阶段处理器的处理:
- Preprocessors(预处理器):顾名思义,处理原始 Markdown 文档。
- Block Processors(块级元素处理器):解析块级 Markdown 语法,比如标题、一段文字、引用块等,最终解析成的 HTML 元素也是块级元素,比如
<h1>、<p>、<blockquote>等。 - Tree Processors(树处理器):根据块级元素处理器处理的结果,进行两方面的操作:
- 调用内联元素处理器:例如
markdown.treeprocessors.InlineProcessor这个类继承于markdown.treeprocessors.Treeprocessor,就是一个树处理器,它负责调用下面的内联元素处理器继续进行内联 Markdown 语法的解析。 - 做一些汇总处理:例如生成目录的
markdown.extensions.toc.TocTreeprocessor也是一个树处理器,它负责在块级元素处理器生成的 HTML 树中把标题<h*>找出来,汇总目录数据后单独生成一份 HTML 树用于目录。
- 调用内联元素处理器:例如
- Inline Processors(内联元素处理器):解析内联 Markdown 语法,比如加粗、链接、行内代码等,最终解析成的 HTML 元素也是内联元素,比如
<strong>、<a>、<code>等。 - Postprocessors(后处理器):顾名思义,处理解析好的 HTML 树。
整个处理流程的关键代码在 markdown.core.Markdown 类的 convert 这个方法里面:
def convert(self, source):
...
# 预处理器
for prep in self.preprocessors:
self.lines = prep.run(self.lines)
# 块级处理器
root = self.parser.parseDocument(self.lines).getroot()
# 树处理器(其中会调用内联元素处理器)
for treeprocessor in self.treeprocessors:
newRoot = treeprocessor.run(root)
...
# 序列化操作
...
# 后处理器
for pp in self.postprocessors:
output = pp.run(output)
...
特殊字符的匹配
其实如果不去了解这个库处理 Markdown 的流程,也很容易猜到对特殊字符的处理应该在内联元素处理器上去自定义,因为要处理的是内联元素,或者叫“行内元素”,即一段文字之中的内容。
内联元素处理器是使用正则表达式去解析 Markdown 语法的,自带的语法解析正则表达式可以在 inlinepatterns.py 中找到,后缀为 _RE 的那些变量就是。所以自己创建两个分别解析引号和 Emoji 的内联元素处理器,也需要分别提供相应的正则表达式。
全角引号的匹配
对于引号,正则表达式很简单,使用 [“”’‘]+ 就行:
- 方括号
[]定义一个字符集,表示匹配字符集内任意字符。 - 引号
“”’‘就是上面说的要匹配的字符集。 - 加号
+表示匹配它前面的正则表达式至少一次。
所以这个正则表达式就表示“匹配一个或多个连续的单/双引号”。
Emoji 的匹配
而对于 Emoji,情况要复杂些,因为我没能想到比较全面的、能正确匹配所有 Emoji 的正则表达式,毕竟 Emoji 字符非常多,不像引号就那么四个,它们在 Unicode 字符集里面也不一定连续,每年还有新的 Emoji 字符标准添加进来。曾经在 网上 找到了一个用 Unicode 字符集范围匹配的正则表达式:
# https://en.wikipedia.org/wiki/Unicode_block
EMOJI_PATTERN = re.compile(
"["
"\U0001F1E0-\U0001F1FF" # flags (iOS)
"\U0001F300-\U0001F5FF" # symbols & pictographs
"\U0001F600-\U0001F64F" # emoticons
"\U0001F680-\U0001F6FF" # transport & map symbols
"\U0001F700-\U0001F77F" # alchemical symbols
"\U0001F780-\U0001F7FF" # Geometric Shapes Extended
"\U0001F800-\U0001F8FF" # Supplemental Arrows-C
"\U0001F900-\U0001F9FF" # Supplemental Symbols and Pictographs
"\U0001FA00-\U0001FA6F" # Chess Symbols
"\U0001FA70-\U0001FAFF" # Symbols and Pictographs Extended-A
"\U00002702-\U000027B0" # Dingbats
"\U000024C2-\U0001F251"
"]+"
)
我亲自试了试,需要把最后一个范围 \U000024C2-\U0001F251 去掉,不然会把汉字也给匹配进去,事实上下面确实有评论指出了类似的问题。基于 Emoji 复杂的情况,再加上我对它其实没有很深入的了解,所以并不想武断地采用这个正则表达式。如果能找到一个 Unicode 官方发布的、可信的匹配 Emoji 的正则表达式,那是再好不过了,可惜我并没有找到。但退而求其次,如果能找到一个由网友不断维护的正则表达式或相关库,也是个不错的选择,于是我找到了 carpedm20/emoji 这个开源库。
Emoji 这个库提供了找出一段文本中 Emoji 及其位置的功能,但实际上并没有简单地提供一个匹配 Emoji 的正则表达式,而是用了一个囊括所有 Emoji 的字典(emoji.unicode_codes.data_dict.EMOJI_DATA)去做查找匹配,核心代码在 emoji.tokenizer.tokenize 这个函数里。由于 Emoji 并不是简单的一个字符一个 Unicode 码点,上文提到的变体选择器 U+FE0E 和 U+FE0F 就是一个例子,它们与 ZWJ(Zero Width Joiner) 码点 U+200D 一起,作为完整全彩 Emoji 的组成部分。例如 U+2708 显示为一架单色“飞机/✈”,附加一个 U+FE0F 则显示为一架全彩“飞机/✈️”;又比如 U+1F636 和 U+1F32B 分别显示为“无语/😶”和“雾/🌫”,在这两个 Unicode 码点之间插入一个 U+200D 则将这两个 Emoji 合并为一个“吞云吐雾的脸/😶🌫”:
>>> print(u'\U00002708')
✈
>>> print(u'\U00002708\U0000FE0F')
✈️
>>> print(u'\U0001F636\U0001F32B')
😶🌫
>>> print(u'\U0001F636\U0000200D\U0001F32B')
😶🌫
然而 Python 是以 Unicode 码点为单位去遍历字符串的,每次迭代获得一个 Unicode 码点,也就是说,上面的全彩“飞机/✈️”会被迭代两次(一次 \U00002708 一次 \U0000FE0F),同理“吞云吐雾的脸/😶🌫”会被迭代三次,所以在做 Emoji 的匹配查找是需要较为复杂的判断的。我简单阅读了一下代码,觉得作者对 Emoji 的了解很深入,除了对上述特殊 Unicode 码点的处理,还对原始 Emoji 字典构建了一个字典树(emoji.tokenizer.get_search_tree)来优化查找性能。更重要的是,这个库更新得比较频繁,相信不会出现错、漏匹配的问题吧。
那么问题来了,既然这个库没有提供匹配 Emoji 的正则表达式,而 Markdown 的内联元素处理器又必须要求一个正则表达式才能去匹配,怎么办呢?
事实上 Emoji 这个库的主要功能是将一段文字里的 Emoji 转换为 :xxx: 形式的代号(称之为“Demojize”),或者反过来(称之为“Emojize”),例如:
>>> from emoji import demojize, emojize
>>> demojize('咱就是说🌧️👸🏻🈚️🍉谢谢')
'咱就是说:cloud_with_rain::princess_light_skin_tone::Japanese_free_of_charge_button::watermelon:谢谢'
>>> emojize('咱就是说:cloud_with_rain::princess_light_skin_tone::Japanese_free_of_charge_button::watermelon:谢谢')
'咱就是说🌧️👸🏻🈚🍉谢谢'
emojize 这个函数恢复的 Emoji 会丢掉变体选择器 U+FE0F,因为“无/🈚️”这个字符显示为单色样式。不过这不重要,根据上文的结论,只要对它单独设置 Emoji 专用字体(例如 Apple 系统中的 Apple Color Emoji),即便没有变体选择器也会显示为全彩样式。既然有这两个操作,那就好办了,即便难以写出匹配 Emoji 的正则表达式,匹配 :xxx: 形式的代号的正则表达式总简单了吧。我的做法是在文本存入数据库之前先使用 Demojize 操作处理,将其中的 Emoji 转换为 :xxx: 形式的代号;从数据库读出之后,使用自定义 Markdown 内联元素处理器解析,提供正则表达式匹配这样的代号,然后使用 Emojize 操作从代号恢复 Emoji 字符。使用的正则表达式为 ((?::[\w\-()]+:)+):
:[\w\-()]+:表示匹配单个:xxx:形式的代号,其中xxx可能是数字、字母、下划线、反斜杠、短横线、括号。((?:yyy)+)表示匹配至少一个yyy匹配的内容,代入:[\w\-()]+:则表示匹配至少一个:xxx:形式的代号。
所以这个正则表达式就表示“匹配一个或多个连续的 :xxx: 形式的代号”。
自定义内联元素处理器
那么继承 markdown.inlinepatterns.InlineProcessor 这个类,创建一个自定义的内联元素处理器 SpecialCharactersInlineProcessor:
InlineProcessor 不同于上面说的树处理器 InlineProcessor,前者是所有内联元素处理器的基类,它自己并不会参与解析,而是由它的派生类去解析,后者则是一个会真正参与解析的树处理器,并且在它之中调用了所有的内联元素处理器。它们位于 inlinepatterns.py、treeprocessors.py 两个不同的文件中,只是名字一样罢了。也不知作者怎么想的,要将两个作用完全不同而又有关联的类定成相同的名字,免不了让初学者困惑啊。from xml.etree.ElementTree import Element
from markdown.inlinepatterns import InlineProcessor
class SpecialCharactersInlineProcessor(InlineProcessor):
def __init__(self, pattern, css_class, md, transformer=None):
super().__init__(pattern, md)
self.css_class = css_class
self.transformer = transformer
def handleMatch(self, m, data):
el = Element('span')
el.set('class', self.css_class)
text = m.group()
if hasattr(self.transformer, '__call__'):
el.text = self.transformer(text)
else:
el.text = text
return el, m.start(0), m.end(0)
为了以后增加对其他特殊字符的处理,为该自定义内联元素处理器预留了扩展能力。可以看到重写了 InlineProcessor 的 handleMatch 这个方法,如果对构造函数提供的正则表达式 pattern 匹配成功,则该方法会被调用,参数 m 的类型是 Match,表示正则表达式的匹配结果,我们可以用它的 group 方法取到匹配的文本,即引号。使用 xml.etree.ElementTree.Element 生成一个 HTML span 标签,将 CSS class 和要单独设置字体的文本添加上去就 OK。对于 Emoji 还需要使用 emoji.emojize 函数从 :xxx: 形式的代号恢复 Emoji 字符,故提供了 transformer 参数提供文本转换。返回的 m.start(0)、m.end(0) 指示消耗的文本长度,告诉调用它的树处理器是否处理了这部分文本。
然后使用该自定义内联元素处理器创建扩展。这里使用参数来区分引号和 Emoji,对两类特殊字符分别创建:
from markdown.extensions import Extension
from emoji import emojize
class SpecialCharactersExtension(Extension):
def extendMarkdown(self, md):
# 引号
md.inlinePatterns.register(SpecialCharactersInlineProcessor(r'[“”’‘]+', 'full-quote', md), 'full_quote', 191)
# Emoji
md.inlinePatterns.register(SpecialCharactersInlineProcessor(r'((?::[\w\-()]+:)+)', 'emoji', md, transformer=emojize), 'emoji', 192)
register 方法用于注册内联元素处理器,其最后一个参数表示内联元素处理器应用的优先级。内联元素处理器是按照优先级顺序应用的,我理解是如果优先级更高的处理器消耗了一段文本,即便这段文本中有可以被优先级更低的处理器消耗的文本,后者也不会有处理的机会了。我觉得一般自己加的处理器都是优先级高一点好吧,内置的内联元素处理器的优先级可以在 markdown.inlinepatterns.build_inlinepatterns 这个函数里面找到,设置成了比内置最高的 190 还大的数字。
这样得到了第一个扩展 SpecialCharactersExtension,稍后会将其应用在 Markdown 解析中。
目录的处理
如果使用了 Markdown 这个库的目录生成扩展(markdown.extensions.toc),那么会发现上面自定义的内联元素处理器没有起作用,事实上这个目录生成扩展 markdown.extensions.toc.TocTreeprocessor 是个树处理器,然而它不像 markdown.treeprocessors.InlineProcessor 这个树处理器,它不会调用任何内联元素处理器。
关键代码在 markdown.treeprocessors.InlineProcessor 中的 run 方法中,最终会调用到 __applyPattern 方法,里面有这么一句是调用了所有内联元素处理器去做内联 Markdown 语法的解析:
for match in pattern.getCompiledRegExp().finditer(data, startIndex):
node, start, end = pattern.handleMatch(match, data)
...
然而在 markdown.extensions.toc.TocTreeprocessor 的 run 方法中,找不到类似的代码。取而代之的是:
- 找出所有的标题
<h*> - 设置跳转 id
- 生成目录数据字典
toc_tokens - 调用
build_toc_div方法,其中递归调用build_etree_ul利用toc_tokens构建目录的 HTML 树
可以看到 TocTreeprocessor 是先生成一个目录数据字典 toc_tokens,再根据这个字典去构建目录 HTML 树。很明显标题 <h*> 中的内容在放入字典时会转换为纯文本,所以之前 markdown.treeprocessors.InlineProcessor 调用所有内联元素处理器添加的子 HTML 元素也全部丢失了。所以目录这块就不是很好处理,难道要去重写 TocTreeprocessor 的 run 方法吗?我不太喜欢这样,复制一大段代码但就只改很少几句。为了简便我还是想在构建目录的 HTML 树过程中嵌入对特殊符号的解析逻辑,很明显最佳的嵌入点是 build_etree_ul,但它是 build_toc_div 方法的一个内部方法,没法去重写,所以最终只好重写 build_toc_div 方法,在它构建好的 HTML 树上去做文章。
我的想法是这样,待 TocTreeprocessor 的 build_toc_div 完成目录 HTML 树的构建,从这个 HTML 树中找到所有 <a> 标签,就是目录的条目了,对它里面的文本进行处理,找出特殊字符用相应 CSS class 的 <span> 标签包裹,跟上文自定义的内联元素处理器 SpecialCharactersInlineProcessor 一样。具体来说,将:
<a>咱就是说“家人们,谁懂啊”,🌧️👸🏻🈚🍉谢谢</a>
处理成:
<a>
咱就是说
<span class="full-quote">“</span>
家人们,谁懂啊
<span class="full-quote">”</span>
,
<span class="emoji">🌧️👸🏻🈚🍉</span>
谢谢
</a>
注意我们拿到的 <a> 标签是一个 Element 对象,它的 text 属性代表其中的文本,但只有第一个文本部分 咱就是说 可以通过 text 属性来设置,剩余的文本部分 家人们,谁懂啊 等需要通过插入的 <span> 标签的 tail 属性来设置,它表示跟随在这个 <span> 标签之后的文本。至于 <span> 标签的插入,使用 SubElement 就行。完整代码如下:
from xml.etree.ElementTree import Element, SubElement
from markdown.extensions.toc import TocTreeprocessor
class SpecialCharactersTocTreeProcessor(TocTreeprocessor):
def build_toc_div(self, toc_list):
div: Element = super().build_toc_div(toc_list)
for a in div.iter('a'):
orig_text = a.text
last_non_sc_start = 0
last_span = None
for scm in special_characters_iter(orig_text):
# 处理非特殊字符部分
text_part = orig_text[last_non_sc_start:scm.start]
if last_span is None:
a.text = text_part if text_part else None
else:
last_span.tail = text_part
last_non_sc_start = scm.end
# 处理特殊字符部分
span = SubElement(a, 'span', {'class': scm.tipe.value})
span.text = scm.chars
last_span = span
if 0 < last_non_sc_start < len(orig_text):
# 处理末尾剩余的非特殊字符部分
last_span.tail = orig_text[last_non_sc_start:]
return div
核心函数是 special_characters_iter,它返回一个对 orig_text 中所有连续的特殊字符组的迭代器:
from typing import Iterator
from re import fullmatch
from emoji.tokenizer import tokenize, EmojiMatch
def special_characters_iter(text: str) -> Iterator[SpecialCharactersMatch]:
merger = SpecialCharactersMerger()
index = 0
for token in tokenize(text, keep_zwj=False):
match = token.value
if isinstance(match, EmojiMatch):
# tokenize 返回 Emoji 的情况
scm = merger.merge(match.emoji, SpecialCharactersType.EMOJI, match.start, match.end)
if scm:
yield scm
index = match.end
else:
# tokenize 返回非 Emoji 字符的情况
if fullmatch(r'[“”’‘]', match):
# 引号
scm = merger.merge(match, SpecialCharactersType.FULL_QUOTE, index, index + 1)
if scm:
yield scm
index += 1
scm = merger.snapshot()
if scm:
# 最后的特殊字符
yield scm
这里用到了上文提到的 emoji.tokenizer.tokenize 函数,它的功能是查找匹配文本里所有的 Emoji 并以迭代器的方式返回,每次迭代得到一个 emoji.tokenizer.Token 命名元组,但它不仅仅只返回查找到的 Emoji,也会返回其他非 Emoji 字符。具体来说,该函数从头遍历文本,当遍历到 Emoji,Token 的 value 属性是 emoji.tokenizer.EmojiMatch;当遍历到非 Emoji 字符,Token 的 value 属性则是 str。其 keep_zwj 参数则表示是否将上文提到的由 ZWJ 码点 U+200D 组合起来的 Emoji 拆开,这里肯定是不拆了。
遗憾的是,tokenize 函数无论返回的是 Emoji 还是非 Emoji,都是以“个”为单位,而不是以“组”,说白了就是如果几个连续的引号或 Emoji 它也会分开返回,如果不加处理就会一个 <span> 块包裹一个引号或 Emoji,当然这样也不是不可以,但我个人希望将连续的特殊字符包裹在同一个 <span> 块中,所以 special_characters_iter 这个函数的主要目的还是进行连续相同类型特殊字符的合并。但为了实现这一需求,必须要拿到每个字符在原始文本中的位置,好在 EmojiMatch 类中不仅包含有 Emoji 字符,还有它的起始与结束位置(注意上文提到有些 Emoji 字符是由多个 Unicode 码点组成的,这些 Emoji 的结束位置并不能是起始位置 +1,这就是为什么同时给出了起始与结束位置),然而对于非 Emoji 字符的情况,就只能拿到这个字符,并没有包含它的位置,所以还使用了 index 来记录当前遍历到的字符结束位置。
当遍历到非 Emoji 字符时,使用 re.fullmatch 正则表达式完整匹配任一个引号 [“”’‘],以排除其他字符。
yield 可以翻译为“生产”,是用于返回迭代器的关键字。顾名思义,每 yield 一次,该函数返回的迭代器完成一次迭代并“生产”一次数据(这里“生产”的数据是 scm),就相当于调用了一次迭代器的 next 方法。但我自己喜欢把它理解为暂时 return 然后“卡在这儿”,然后下次迭代再“恢复执行”。
SpecialCharactersMerger 是一个辅助类,利用它进行连续特殊字符的合并。完整代码如下:
class SpecialCharactersMerger:
def __init__(self):
self._chars = None
"""
保留的连续特殊字符子串
"""
self._type = None
"""
self._chars 的类型
"""
self._start = None
"""
self._chars 在原字符串中的起始位置
"""
self._end = None
"""
self._chars 在原字符串中的结束位置
"""
def _set(self, chars: str, tipe: SpecialCharactersType, start: int, end: int):
self._chars = chars
self._type = tipe
self._start = start
self._end = end
def snapshot(self):
if not self._type:
return None
return SpecialCharactersMatch(self._chars, self._type, self._start, self._end)
def merge(self, chars: str, tipe: SpecialCharactersType, start: int, end: int):
if not self._type:
# 找到的第一个特殊字符
self._set(chars, tipe, start, end)
elif self._type == tipe and self._end == start:
# 相同类型字符且连续,合并
self._chars += chars
self._end = end
else:
# 字符类型不同或不连续
ret = self.snapshot()
self._set(chars, tipe, start, end)
return ret
return None
该类保留着目前遍历到的最新一组连续特殊字符信息。在 special_characters_iter 中,当 tokenize 再次遍历到特殊字符时,调用 merge 方法传入新的特殊字符:
- 如果没有保留的特殊字符,则调用
_set初始化(if分支)。 - 否则将该类保留的特殊字符与传入的特殊字符作比较,如果两者类型相同且连续,将它们合并并继续保留(
elif分支)。 - 否则将该类当前保留的特殊字符信息包装在一个命名元组
SpecialCharactersMatch中返回,并重新初始化保留的特殊字符为传入的特殊字符(else分支)。
特殊字符类型使用枚举 SpecialCharactersType 定义,其中 value 是包裹特殊字符的 span 标签的 CSS class 名称:
from enum import Enum
class SpecialCharactersType(Enum):
FULL_QUOTE = 'full-quote'
EMOJI = 'emoji'
以及包装特殊字符信息的命名元组 SpecialCharactersMatch:
from typing import NamedTuple
class SpecialCharactersMatch(NamedTuple):
chars: str
tipe: SpecialCharactersType
start: int
end: int
type 是 Python 的内置关键字,所以换成 tipe。然后使用该自定义目录树处理器 SpecialCharactersTocTreeProcessor 创建扩展。由于 markdown.extensions.toc.TocExtension 已经重写了 extendMarkdown 方法,其中有注册 TreeProcessorClass 指定的树处理器的逻辑,因此直接重写 TreeProcessorClass 即可:
from markdown.extensions.toc import TocExtension
class SpecialCharactersTocExtension(TocExtension):
TreeProcessorClass = SpecialCharactersTocTreeProcessor
这样得到了第二个扩展 SpecialCharactersTocExtension,稍后会将其应用在 Markdown 解析中。
应用 Markdown 扩展
上文我们得到了两个新扩展:SpecialCharactersExtension 和 SpecialCharactersTocExtension,分别用于普通文本和目录的特殊字符处理。最后就可以将它们应用在 Markdown 解析中了:
from markdown import markdown
processed = markdown(text, extensions=[SpecialCharactersExtension(), SpecialCharactersTocExtension()])
这样,在 markdown 函数返回的 processed 中,text 里面连续的引号会自动被包裹上 <span class="full-quote"></span>,连续的 Emoji 则会被自动包裹上 <span class="emoji"></span>,从它生成的目录也会有同样的处理。再在前端定义好上文提及的 CSS 样式就 OK 啦。看看效果:
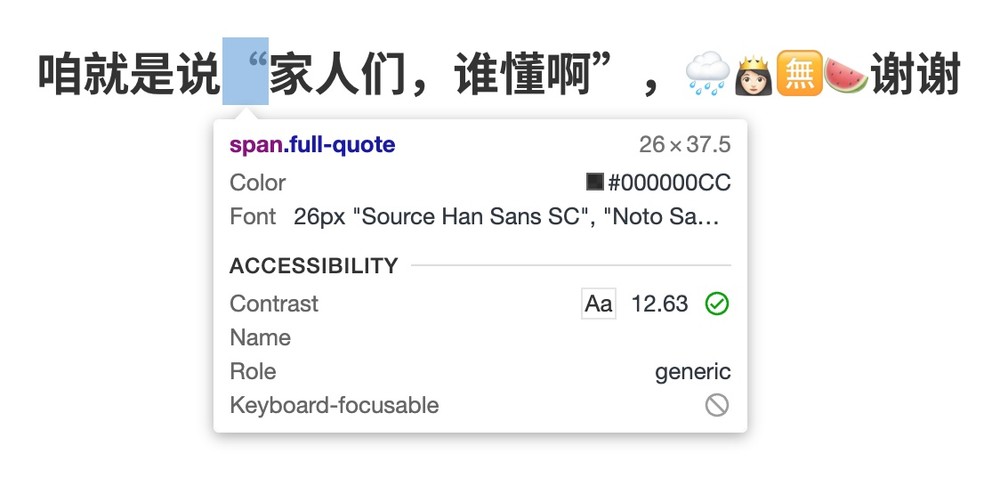

嗯,确实很美观呢。
缺点与前端的补充处理
当然上文所述单独设置字体的方案也并不完美。目前我发现两个明显的缺点,一是引号所用的中文字体也需要遴选,不是所有的中文字体的引号都是与汉字等宽的样式;二是网站上所有可能出现引号或 Emoji 的文本都需要做这样的处理,太过麻烦。但可以在前端进行一些处理,以弥补这两个缺点。
统一引号字体
首先聊聊第一个缺点,引号所用字体的区别。不是所有操作系统都是预装了思源黑体的,而上文所述让引号显示为全角样式的方案完全依赖于设备上安装有该字体,如果网站访客没有安装怎么办呢?较新版本的 macOS 会 fallback 到 PingFang SC(苹方),较新版本的 Windows 则会 fallback 到 Microsoft YaHei(微软雅黑)。以 macOS 为例,苹方这款中文字体的双引号样式却是不与汉字等宽的(圆点 + 一撇):

更何况较新版本的 Safari 由于所谓的“安全原因”,已经禁用 font-family 指定非系统自带字体的能力了,也就是说,即使我自己电脑上安装有思源黑体,把它放到 font-family 里面是没有任何效果的,Safari 会直接无视它而选择下一个字体,但从网络加载的字体和系统自带字体不会受影响。例如上文提到的 CSS class full-quote 实际上使用的是排在思源黑体之后的苹方。
另外跟上文提到的 Emoji 一样,不同浏览器对引号的显示也有区别。经过我的测试,若 font-family 中某个包含引号字形的西文字体被成功应用,Chrome(版本 114)会将引号显示为该字体的半角样式(一撇),而 Safari(版本 16.5)却会将引号显示为“苹方”字体,即上述“不与汉字等宽”的样式,我觉得这可能是 Safari 对中文排版做的一项优化。但有意思的是,Safari 貌似只针对双引号作了优化,单引号依旧显示的该西文字体的半角样式。

那么如何让引号在所有设备上的样式都是一致的呢?既然 Safari 不会禁用从网络加载的字体,我的解决方式是,使用方案一“制作字体”来统一引号字体,但不是自己制作字体并托管,而是上文提到的我以前对引号的适配方案,从 Google Fonts 引用思源黑体,使用 text 参数限制字符集为引号,只是这里引用的不是繁体而是简体。
<link href="https://fonts.googleapis.com/css2?family=Noto+Sans+SC&display=swap&text=%E2%80%9C%E2%80%9D%E2%80%99%E2%80%98" rel="stylesheet">
这样应用上述 font-family,如果设备上未安装思源黑体,浏览器会从 Google Fonts 加载引号;而如果设备上有安装思源黑体,Safari 则也会从 Google Fonts 加载引号,保证了引号在所有设备上显示的一致性。
前端 JavaScript 解析
第二个缺点是,上文所述单独设置字体的方案仅适用于需要解析 Markdown 的文本,在我的网站中,只有文章正文、摘要、目录部分适用该方案,而其他位置的文本也可能包含引号或 Emoji,例如文章标题,如果还将它们当作 Markdown 解析一遍,属实是“大材小用”了。更何况有时候前端是需要未经处理的原始文本的,例如将文章标题设置为网页标题。难道后端还要返回两份内容,一份处理过的,一份没处理的?
对此,我的做法是这类无需 Markdown 解析而又有可能包含特殊字符的文本,还是交给前端去解析吧。那么跟后端一样,前端也需要一个用于匹配 Emoji 的开源库,我找到的是 mathiasbynens/emoji-regex,顾名思义它提供了专门用来匹配 Emoji 的正则表达式(在 index.js 中),这一点是与后端所用的库通过字典匹配有所区别的。
具体的解析方式也很简单,直接使用 JavaScript 字符串的 replace 函数来将文本中的特殊字符替换成被 <span class="xxx"></span> 包裹的形式即可。但与后端一样,emoji-regex 这个库只支持匹配单个 Emoji,需要将它改造成可以匹配多个连续 Emoji 的形式。
import emojiRegex from "emoji-regex";
const FULL_WIDTH_QUOTE_REGEXP = /[“”’‘]+/g;
const EMOJI_REGEXP = new RegExp(`((?:${emojiRegex().source})+)`, "g");
emojiRegex 就是一个正则表达式 RegExp 对象,通过 source 取得它的正则表达式字符串,外面跟后端一样包上 ((?:yyy)+) 即可。g 是 JavaScript 正则表达式的修饰符,表示 global 全局匹配。
为预留扩展能力,写一个 stylize 函数匹配并替换任意特殊字符:
function stylize(text: string, regExp: RegExp, cssCls: string) {
return text.replace(
regExp,
(match) => `<span class="${cssCls}">${match}</span>`
);
}
stylizeSpecialCharacters 函数处理引号和 Emoji 两类特殊字符:
function stylizeSpecialCharacters(text: string) {
let ret = text;
ret = stylize(ret, FULL_WIDTH_QUOTE_REGEXP, "full-quote");
ret = stylize(ret, EMOJI_REGEXP, "emoji");
return ret;
}
对于每一个可能包含引号或 Emoji,而又不由后端进行 Markdown 解析的文本,都需要先用 stylizeSpecialCharacters 处理一遍再放到页面上去。实在觉得太麻烦,对于引号来说,还可以用提取字形制作新字体这个方案,对于 Emoji 来说,也没有什么更好的办法了。
总结
上述内容可能写得比较杂乱,现作一个简单的总结。首先核心思想是将特殊字符用 <span class="xxx"></span> 包裹,然后在前端设置相应的 CSS 样式实现“单独设置字体”。我的网站是后端解析 Markdown,所以在网页各处可能出现引号、Emoji 等特殊字符的文本中,需要 Markdown 解析的,则放在后端与 Markdown 解析一同处理,把特殊字符视作 Markdown 语法,然后编写相应的处理器即可,其中自定义了内联元素处理器 SpecialCharactersInlineProcessor,对于目录,还需自定义树处理器 SpecialCharactersTocTreeProcessor;无需 Markdown 解析的,则放在前端单独解析,直接替换特殊字符。以及,为了实现引号在所有设备上都显示为一致的思源黑体全角样式,单独从 Google Fonts 引用引号字形。